- 27 janvier 2021
- Envoyé par : IMBA CONSULTING
- Catégorie: IMBA-Blog

Rise of the streaming use cases
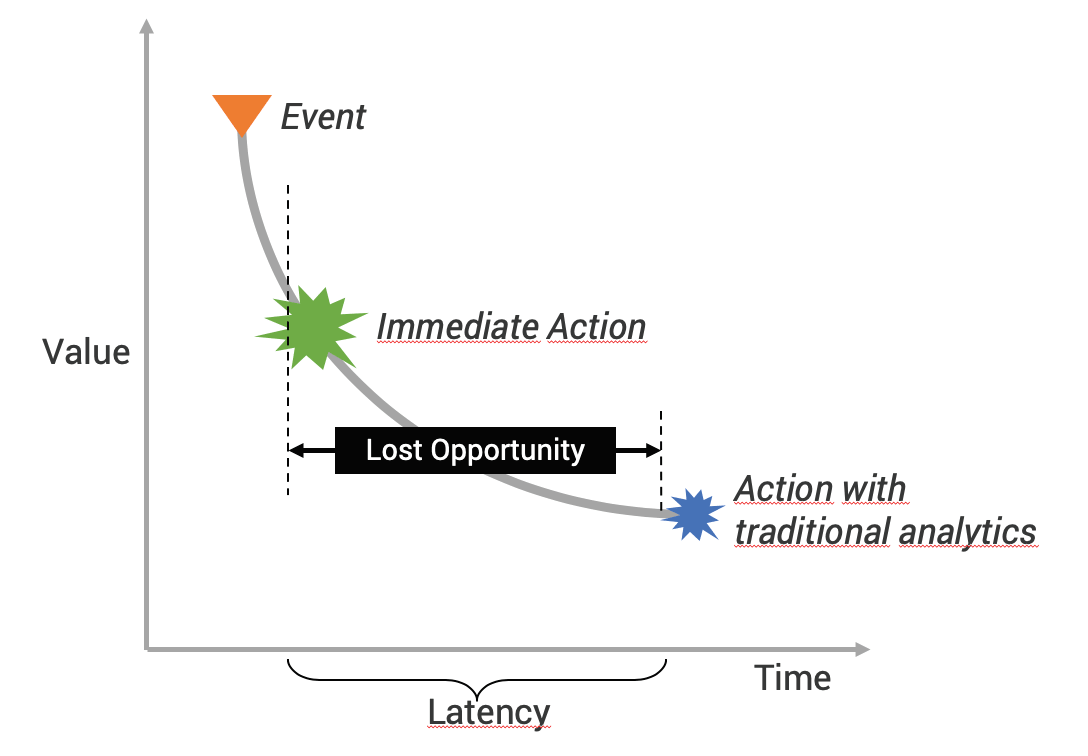
In 2019, a study by Lightbend and The New Stack [1] revealed that The use of stream processing for AI/ML applications increased four-fold in two years and they expect that it will keep increasing in the coming years. This rise of streaming use cases is related to the fact that real time data has increased tremendously over the past years as never seen before. Think about all those connected devices and people generating unbounded data 24/7. This huge amount of real time data needs to be analyzed as soon as possible because it’s value diminishes over time. Organizations need to take immediate action on their data when it is fresh otherwise they will lose out on business opportunities [Figure-1]. With that being said, modern data driven enterprises have no choice but to adopt the streaming paradigm to address their challenges.
Delta Lake as a key player in modern streaming architecture
Delta lake is an open source Linux foundation project, initially developed by Databricks. Combined with Spark Structured Streaming, Delta gives data engineers the opportunity to build more reliable streaming architectures. Indeed, with it’s ACID guarantees, scalable metadata handling and the ability of unifying streaming and batch, Delta lake took the streaming data processing to the next level by providing more robustness and reliability to the streaming data pipelines. But even using Delta, complexity remains a real challenge that prevents enterprises from easily extracting insights from their streaming data. In the next section we will tackle a very classical streaming use case and see how Delta lake and Spark Structured Streaming can be leveraged to address it.
CDC as a streaming use case
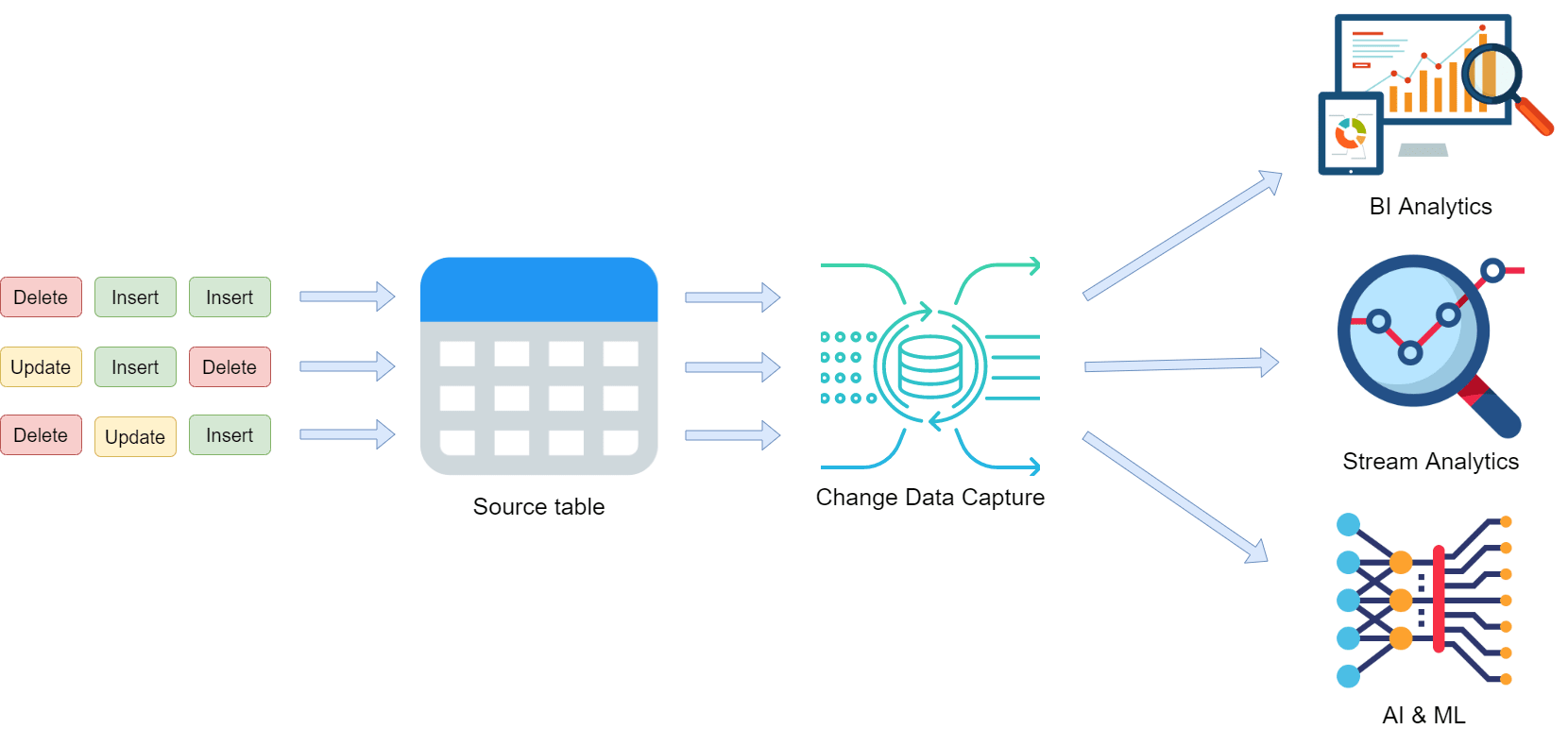
To ensure enterprises don’t miss the opportunities in perishable insights, it’s essential to have a means to rapidly detect any operation occurring on the data. CDC (Change Data Capture) systems assure this by continuously capturing changes applied on a given dataset. Those Changes can be inserts of new data, update, delete of existing data or even modifications in the metadata (schema evolution for example). Then the detected changes need to be downstreamed to various destinations, helping organizations to develop actionable data for various use cases such as systems synchronization, streaming analytics and building machine learning models. [Figure-2]
Is Implementing CDC on top of Delta really challenging?
The first challenge we faced when we started working on the CDC use case is that streaming from Delta tables does not handle input that is not an append and throws an exception if any modifications occur on the table being used as a source. If a Merge, update or delete command is run on a Delta table, all the downstreams consuming from the table will be broken. This deprives data engineers using Delta from a powerful weapon which is the rich DML api that Delta offers and presents a headache for architects designing scalable and composable streaming pipelines. As a workaround for this, Delta gives users an option option(“ignoreChanges”, “true”) that can be activated on the downstreams consuming from a Delta table. When modifications occur on the source, consumers will not be disrupted. Also, Using this option, downstreams will be able to detect updates applied on the Delta table. But there are no guarantees that only modified data will be propagated. Unchanged data may still be emitted. Therefore downstream consumers should handle duplicates which can be an expensive operation for streaming pipelines and adds more complexity to the existing architecture. Besides the debt introduced by such a solution, it does not entirely solve the problem because even when using it, delete operations are not propagated downstream. While this can be helpful for some use cases, it’s not the case for many others where users need to propagate all types of modifications applied to the data in an accurate and efficient manner without introducing any additional complexity to the existing architecture. CDC is one of those use cases.
Delta Streams at the rescue
Delta Streams is a project developed by DataBeans on top of Delta lake that simplifies streaming architectures. It provides data engineers with rich, straightforward and intuitive apis that help them solve their complexe streaming use cases in a simple and efficient manner.
How to use Delta Streams to solve the CDC use case ?
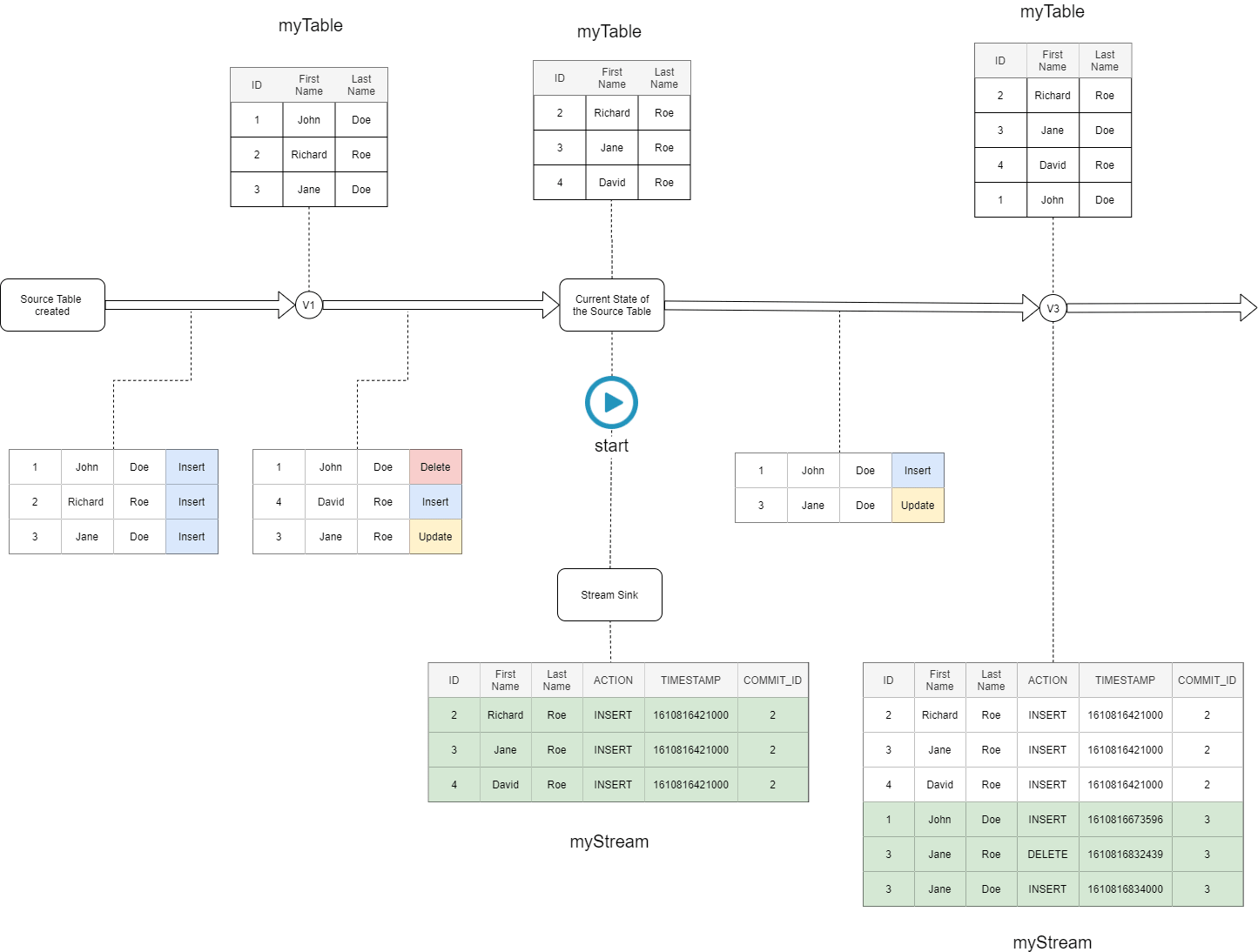
If we ask any data engineer about his vision of a perfect CDC implementation, the answer would be quite simple: we should be able to create a stream that points to a Delta table, detect all the changes and downstream them to various destinations for further analysis. All of this with a complete abstraction over the technical complexity. Because Delta Streams is a solution designed by data engineers for data engineers, you’re getting exactly what you are hoping for to implement the CDC use case. [Figure-3] shows how the Delta Streams api handles the CDC use case.

Conclusion
With Delta Streams, we are removing complexities for Data Engineers and accelerating the end-to-end streaming pipelines. In this article we just showcased CDC as a challenging streaming use case that Delta Streams handles in a very simple and intuitive way. But this is just the beginning, a glimpse of the capabilities of Delta Streams, stay tuned as more features from Delta Streams will be revealed soon.