- 18 février 2021
- Envoyé par : IMBA CONSULTING
- Catégorie: IMBA-Blog

Introduction
Open sourced in April 2019, Delta Lake is a Databricks project that brings reliability, performance and lifecycle management to data lakes. In October 2019, the Delta Lake Project was hosted by the Linux Foundation to Become the Open Standard for Data Lakes. In this article we will have two parts. In the first one we will explore the challenges facing data engineers while building data pipelines. While in the second one we will introduce the Delta Lake project, its key concepts and features, and how it offers an elegant solution to build reliable performant data pipelines.
A data engineer’s sad story
Bob is an enthusiast data engineer. He is hired by a company specialized in data analysis to build modern, robust data pipelines. His first task is to design a data pipeline that reads raw data, normalize it and then compute some aggregations on it.

Data files will be received in an immutable persistent read only staging area. A first Spark job will normalize data from the source, apply technical controls on it and then store results in columnar storages format (ex: Parquet). A second Spark job will read the normalized data, perform some aggregation on it and expose results to the end users.
Challenge 1: Reproducibility
Bob thought that he made it but this is just the beginning. Unfortunately, mistakes happen! received data could be corrupted or incomplete and computation could fail especially when running in distributed systems. Also business rules evolve constantly and adjustments on already computed results are frequently requested. So the ability to reprocess data is a must! We need to be able to apply the same computation logic (already applied on the corrupted or incomplete data) on the corrected data and replace the faulty results with the rectified ones. It’s also imperative to be able to adjust the compute logic and update the results. So Bob’s team asked him to figure out a solution for this challenge.
To make his data pipeline reproducible, Bob partitioned the tables with processing date so his unit of work would be immutable. He also made his spark jobs write data in overwrite mode (at the partition level) so the job would be deterministic and idempotent. This way, when computation fails or business logic needs to be modified, he just needs to re-run the job and the results will be replaced with the correct data without applying any complex manual procedure to delete faulty results and replace it with the correct one.

Bob was starting to have a better understanding of the data engineer’s job and the challenges that come with it. He was doing his best to deliver solutions in the most fast and efficient way possible, that hasn’t gone unnoticed. Since no good deed goes unpunished, his manager decided to make him work on the most challenging subjects of the year: the integration of new sources to the existing pipeline and GDPR (right to be forgotten).
Challenge 2: Multi Sources
Bob is now starting to become one of the most valuable professionals in his team and he must meet those expectations. He must prove that the first success was not beginner’s luck.
The company wanted to correlate data from different sources. That means that the data should be collected from those sources and the pipeline should be able to handle all of them in a scalable and efficient way.
Bob adapted the pipeline to get data from multiple sources ensuring that the unit of work keeps immutable. To overcome this challenge, he added the source name to the partitioning columns.
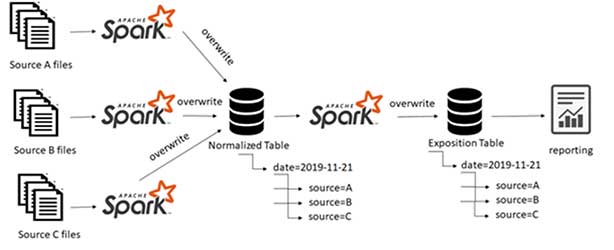
Challenge 3: Many Small Files
Lately, and for the first time, Bob stumbled into performance issues on the pipeline. After drilling down into the problem he found out that the performance bottleneck is due to thin partitioning that generated small files, those small files, accumulated over time into a large number, slowing down performance considerably.
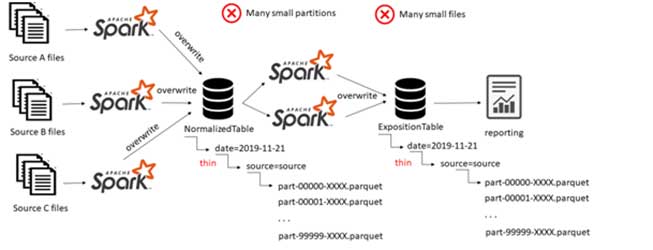
It turns out, each file comes with its own overhead of milliseconds due to opening the file, reading metadata, loading data and closing it. All these milliseconds will easily add up to hours of waiting for results, which will slow down any read operation from the table.
The data discovery phase could also be problematic, the file listing operation does not scale well and could eventually take a long time because it’s proportional to the number of files, this problem is related to the file system.
We hit the small file problem when data gets loaded incrementally and it gets progressively worse if the incremental loads are more frequent.This type of situation is commonly encountered with the output of streaming applications. Depending on how often those applications write out data, we can potentially end up with poorly compacted data.
Think about a streaming use case where streaming data keeps being inserted into the table every couple of minutes, we will end up with millions of small files.
In this case a job that consolidates small files into larger ones that are optimized for read access would solve the problem. But in order to be certain that this solution is doable Bob showed the problem to a senior data engineer colleague.His colleague told him that it’s a well known problem and a compaction job would solve it, this is when Bob started to sense a « but » coming , and he was right. The problem is that this solution does not take into account that the user can read the data while the compacting process is still running resulting in partial or duplicated data.
Since we have no atomic operation guarantee any read could overlap with the compaction operation. Read operations should read from an isolated, consistent state of the table.
Implementing the compaction job could be a complex task (this can be a subject of a whole separate blog).
Another side effect that Bob noticed with such pipeline architecture is the huge number of partitions. Multiplying partition entries will create overhead on the Metastore that manages all metadata, this could eventually overwhelm the Metastore.
It is therefore recommended to partition wisely depending on the column cardinality and the business access patterns, this could be a very challenging task. Even though those recommendations are still reasonable, it is still very case-sensitive, so partitioning must be fine-tuned according to a given scenario. Bob found himself facing a complicated situation, such partitioning is the sticking point of the problem, changing it, will break the immutability of the unit of work. That way he will return to the starting point.
Challenge 4: Concurrency handling
A business analyst from Bob’s team claimed that the data visualized in one of the dashboards is incomplete, Bob verified all the operations feeding the exposition table and found what seemed to be the cause of the problem: the user read from the table while the writing is still in process. This is known as partial read.
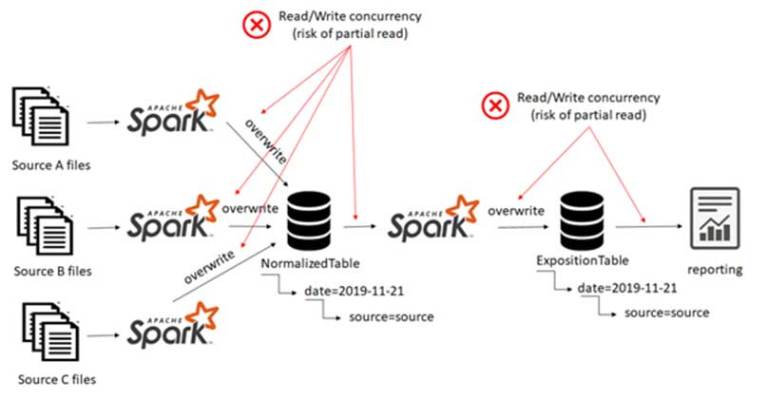
Bob spent many hours trying to solve the concurrency problem and he found what seemed to be a solution: a scheduling that garanties that read and write operations will never overlap should solve such a problem. But the thing that killed all Bob’s hope is the inefficiency of this solution for streaming use cases . . .
Challenge 5: GDPR (the right to be forgotten)
Bob’s company is storing hundreds of terabytes of data in their data lake. This large dataset is stored in different locations. Deleting specific user data can be very challenging because data in data lake are not indexed and delete action requires large table scan, it’s like finding a needle in a haystack. Taking a brute force approach to GDPR compliance can result in multiple jobs operating over different tables, resulting in weeks of engineering and operational effort in addition to excessive resource usage that can be very expensive. This operation could be very time and resource consuming. Also, since the delete/update logic could only be applied at the partition level, to delete a single row, we have no choice but rewriting whole partitions containing a huge amount of data. Besides that, there is no native support for delete and update operations, which means that data engineers have to implement the delete/update logic themselves. Furthermore, since typical data lake offerings do not provide ACID transactional capabilities, no snapshot isolation is guaranteed so the delete/update can impact the consistency of read/write operations on the data.
 Challenge 6: Data Quality
Challenge 6: Data Quality
When thinking about data applications, as opposed to software applications, data validation is vital because without it, there is no way to gauge whether something in your data is broken or inaccurate. Data quality problems can easily go undetected. Edge cases, corrupted data, or improper data types can surface at critical times and break your data pipeline. Worse yet, data errors like these can go undetected and skew your data, causing you to make poor business decisions.
Unfortunately this is what happened to Bob, he made some modifications to the job that writes data into the normalized table and unintentionally modified the schema. The job that reads data from the normalized table crashed as it got a schema different from the expected one.
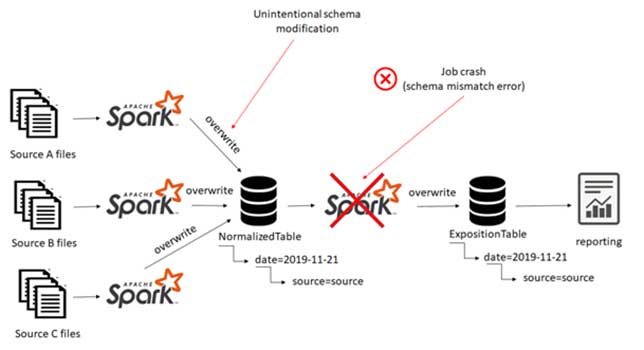
The error is due to the data-handling strategy of the data lake known as Schema-on-read. The data from the source was written without being validated to the table schema, at the moment of reading the validation against the schema caused the problem. A Schema-on-write approach would solve this problem by enforcing the schema validation on write.
Finally
The problems are stacking up and Bob has no idea how to solve them. Each time he gets close to the solution, he faces the same obstacles. A vicious cycle of problems that could cost Bob his success. Sadly, Bob is now at a dead end and his superior’s schedule and expectations are putting pressure on him.